Student(s): Enrique Barrueco Mikelarena, Jan Kunnen, Guus Eijsvogels, Maxime Duchateau, Georgios Koutidis, Francesca Battipaglia;
Supervisor(s): Prof. Gerhard Weiss;
Semester: 2020-2021;
Problem statement and motivation:
Dynamic pricing is the concept of a vendor, retailer or other organization that sells products or services adjusting its selling price according to some sort of decision functions in order to reach an objective – e.g. maximizing profit or revenue. Based on a different set of input factors the price the consumer has to pay changes. The big question is how to set the prices such that the aimed objectives are reached as optimal as possible.
A simple example of a market that is subjected to dynamic pricing is the market of airline tickets. Another example is the pricing strategies of world-leading e-commerce provider Amazon (Chen, Mislove, & Wilson, 2016).
A large amount of literature applies the techniques in the field of automated dynamic pricing to a very specific market. The model we want to present tries to address the lack of a general model, that can be used in every type of market. Of course, this can be hard due to the different characteristics of different markets, but some sort of generalization should be possible.

According to Forbes dynamic pricing is “the secret weapon market leaders in different domains of business use to reach their success”. Dynamic pricing however is complex. It is a result from a system that incorporates both a complex demand function and supply function that influence each other, which are also influenced by a lot of internal and external factors on its own (Bitran & Caldentey, 2003). Moreover, the difficulty of implementing a dynamic pricing model is related to the scarce data availability. Due to strategic reasons, firms are not eager to share the information.
Markov Decision Process
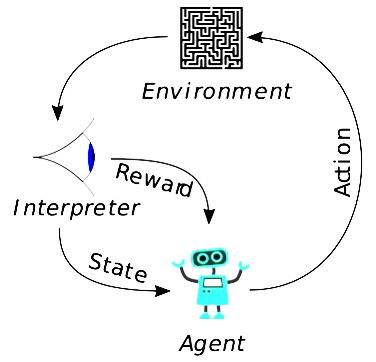 The price learning process can be expressed as a Markov Decision process. The latter involves the definition of a State space, which, in our case, represents the historical data throughout the time horizon. The place where the agent starts its learning process represents the Initial state. In order to move from one state to another, the agent can choose from a definite set of actions, which determine the Action space. All the state-action pairs define the model environment. To each state-action pair is related a reward, that is the expected outcome while following a specific policy.
The price learning process can be expressed as a Markov Decision process. The latter involves the definition of a State space, which, in our case, represents the historical data throughout the time horizon. The place where the agent starts its learning process represents the Initial state. In order to move from one state to another, the agent can choose from a definite set of actions, which determine the Action space. All the state-action pairs define the model environment. To each state-action pair is related a reward, that is the expected outcome while following a specific policy.
Markov decision processes are dynamic and, for this reason, they can be used to define optimal prices, which, in turn, are dynamic throughout the time.
Research questions/hypotheses:
- Which is the best definition of a Markov process in this field?
- Which parameters influence the demand function most?
- What is the effect of data scarcity on the efficiency of the model?
- Primary goal: Which model is the most efficient?
Main outcomes:
The main outcomes of the project so far have been:
- Creating our own dataset scraping data from AliExpress and Alibaba websites. The dataset will be published online and can be used for other reaserches.
- Definition of demand and cost functions. In this way it is possibile to determine the profit related to different prices and the related demand.
The planned future outcomes are:
- A fully expanded dataset. This means that more parameters will be taken into account and, hence, the model will be more realistic.
- Implementation of different Q-learning models.
- Comparison between the models’ efficiency. In this way is possible too see which of the methods performs better on that specific task.
- Creation of automated dynamic pricing model. The final model will be able to propose the best price, given the parameters considered and the performance indicator we want to optimize.
- Generalization performance of dynamic pricing model. The model should be applicable to different kinds of markets, regardless the specific characteristics of each market.
References:
Chen, L., Mislove, A., & Wilson, C. (2016). An empirical analysis of algorithmic pricing on amazon marketplace. In Proceedings of the 25th international conference on world wide web (p. 1339–1349). Republic and Canton of Geneva, CHE: International World Wide Web Conferences Steering Committee. Retrieved from https://doi.org/10.1145/2872427.2883089 doi: 10.1145/2872427.2883089
Bitran, G., & Caldentey, R. (2003, Summer). An overview of pricing models for revenue management. Manufacturing Service Operations Management, 5(3), 203. Retrieved from https:// search-proquest-com.dianus.libr.tue.nl/docview/200628820?accountid=27128
Figures references:
https://en.wikipedia.org/wiki/Reinforcement_learning#/media/File:Reinforcement_learning_diagram.svg
https://www.forbes.com/sites/forbestechcouncil/2019/01/08/dynamic-pricing-the-secret-weapon-used-by-the-worlds-most-successful-companies/



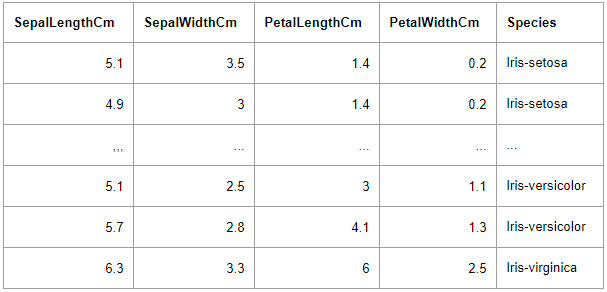
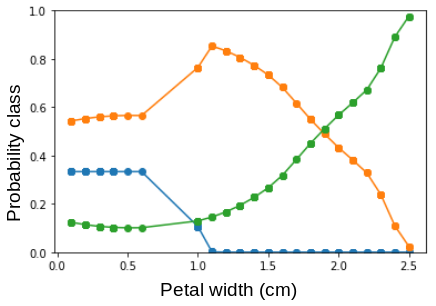
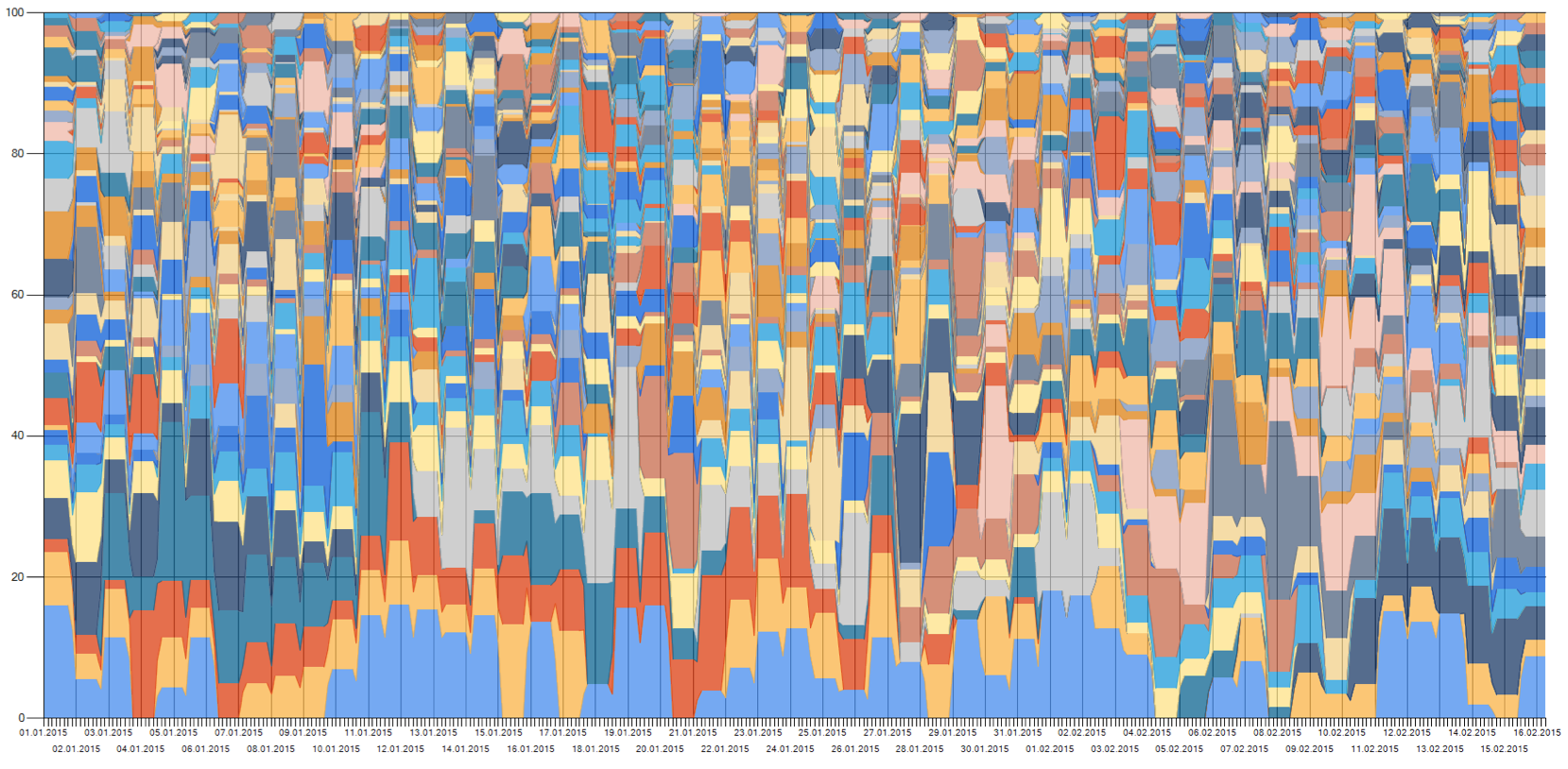
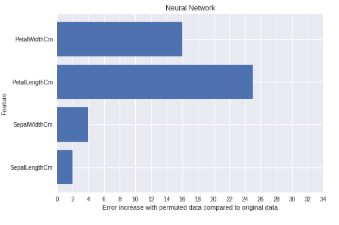 we can see that when the values for the length of the petal (PetalLengthCm) are changed, the prediction error increases by almost 25 percent, indicating that the petal length was important to predict which flower it is. Since the values of the other features are smaller petal length is also the most important feature.
we can see that when the values for the length of the petal (PetalLengthCm) are changed, the prediction error increases by almost 25 percent, indicating that the petal length was important to predict which flower it is. Since the values of the other features are smaller petal length is also the most important feature.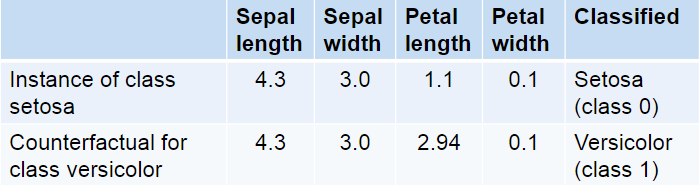
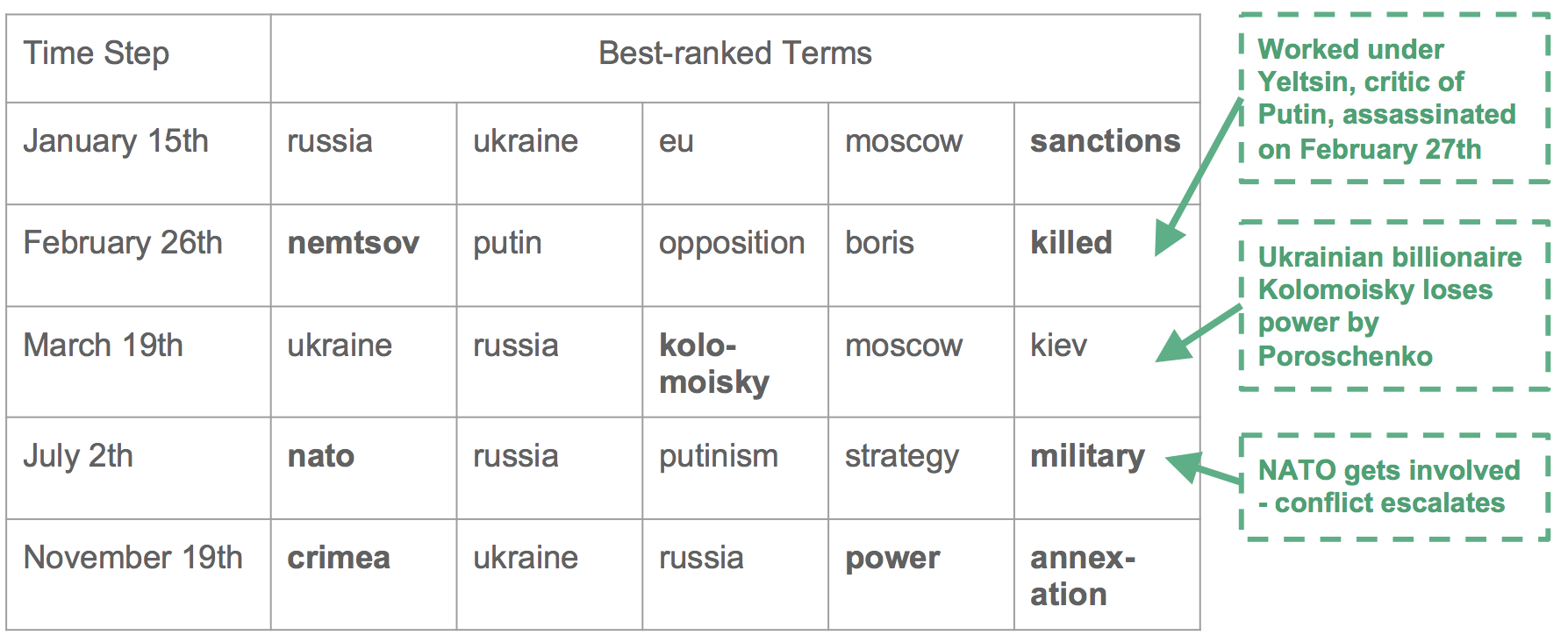
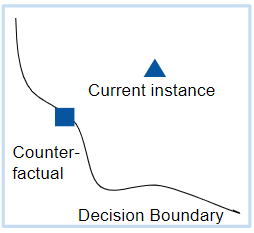 Counterfactuals can be used to get information about how accurate the prediction of the black box model are. Because if the counterfactual is very close to the explained instance, it could be the case that the prediction of the model was wrong. On the other hand, if the distance is big the chance that the model is wrong is very small.
Counterfactuals can be used to get information about how accurate the prediction of the black box model are. Because if the counterfactual is very close to the explained instance, it could be the case that the prediction of the model was wrong. On the other hand, if the distance is big the chance that the model is wrong is very small.