Student(s): Daniel Brüggemann, Yannik Hermey, Carsten Orth, Darius Schneider, Stefan Selzer;
Supervisor(s): Dr. Gerasimos (Jerry) Spanakis;
Semester: 2015-2016;
Problem statement and motivation:
Growth of internet came along with an increasingly complex amount of text data from emails, news sources, forums, etc. As a consequence, it is impossible for a single person to keep track of all relevant text data in most cases and moreover to detect changes in trends or topics. Every company (and every person) would be interested to harness this amount of free and cheap data in order to develop intelligent algorithms, which are able to react to emerging topics as fast as possible and at the same time track existing topics over long time spans. There are many techniques about topic extraction (like Nonnegative Matrix Factorization (NMF) or Latent Dirichlet Allocation (LDA) [Blei et al., 2003]) but there are not many extensions to dynamic data handling. The goal of this project is to explore LDA (or other techniques) as a technique to detect topics as they appear and track them through time. Corpus can be the (fully annotated and immediately available) RCV1 Reuters corpus (810.000 documents) and/or the actual Reuters archive.
Research questions/hypotheses:
-
How to detect, track and visualize topics in a large document collection, that dynamically change in the course of a certain time span?
Main outcomes:
-
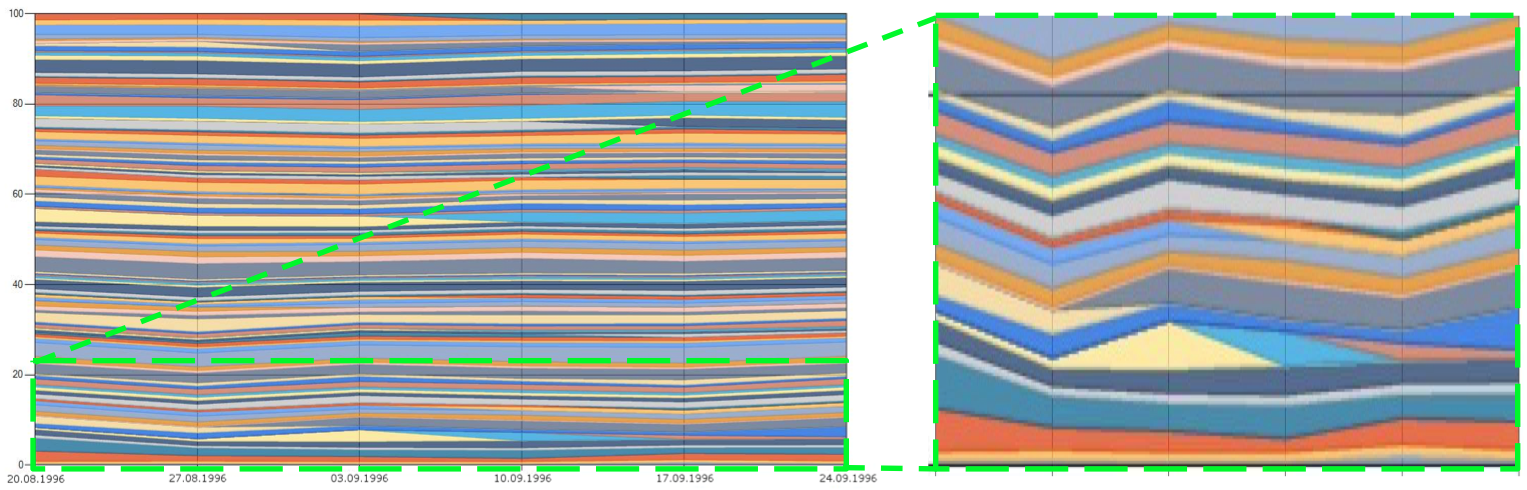
This report presents two approaches to detect evolving and dynamically changing topics in a large document collection, and visualizes them in the form of a topic river, allowing for easy and direct association between topics, terms and documents.
-
The LDA dynamic topic model was researched and applied to the news articles of the 6 weeks in August and September 1996 of the Reuters corpus RCV1. After applying careful preprocessing, it was possible to identify some of the main events happening at that time. Examples of detected topics are with the corresponding main word descriptors are:
Child abuse in Belgium: child, police, woman, death, family, girl, dutroux
Tropical storm Edouard: storm, hurricane, north, wind, west, mph, mile
Peace talks in Palestina: israel, peace, israeli, netanyahu, minister, palestinian, arafat
Kurdish war in Iraq: iraq, iraqi, iran, kurdish, turkey, northern, arbilSummarizing the LDA based approach, the dynamic topic model produces topics, that are on a more generalized level, at least when the same number of topics is chosen, similar to the annotated topics. A high frequency of topic evolvement can not be seen here.
-
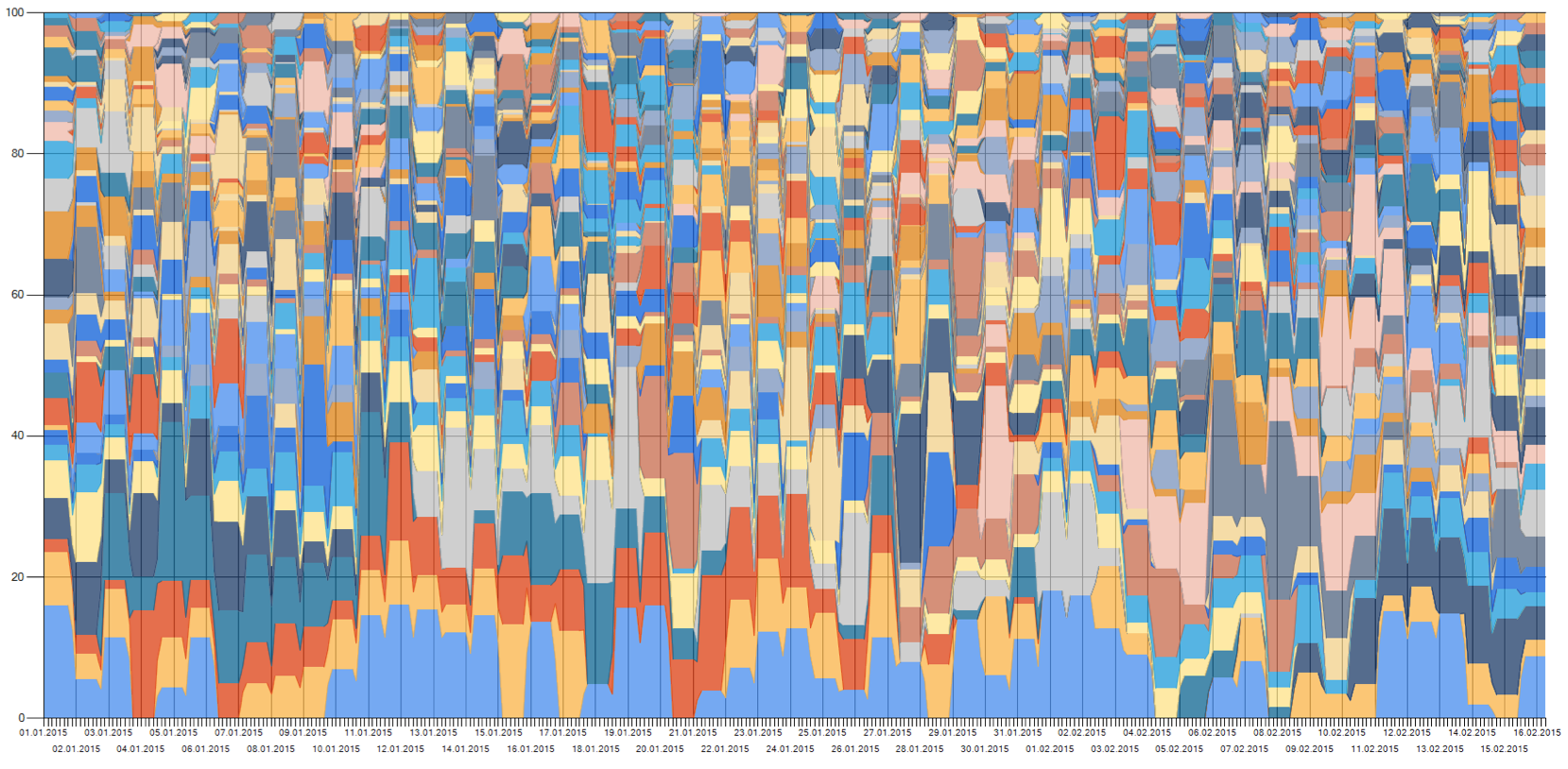
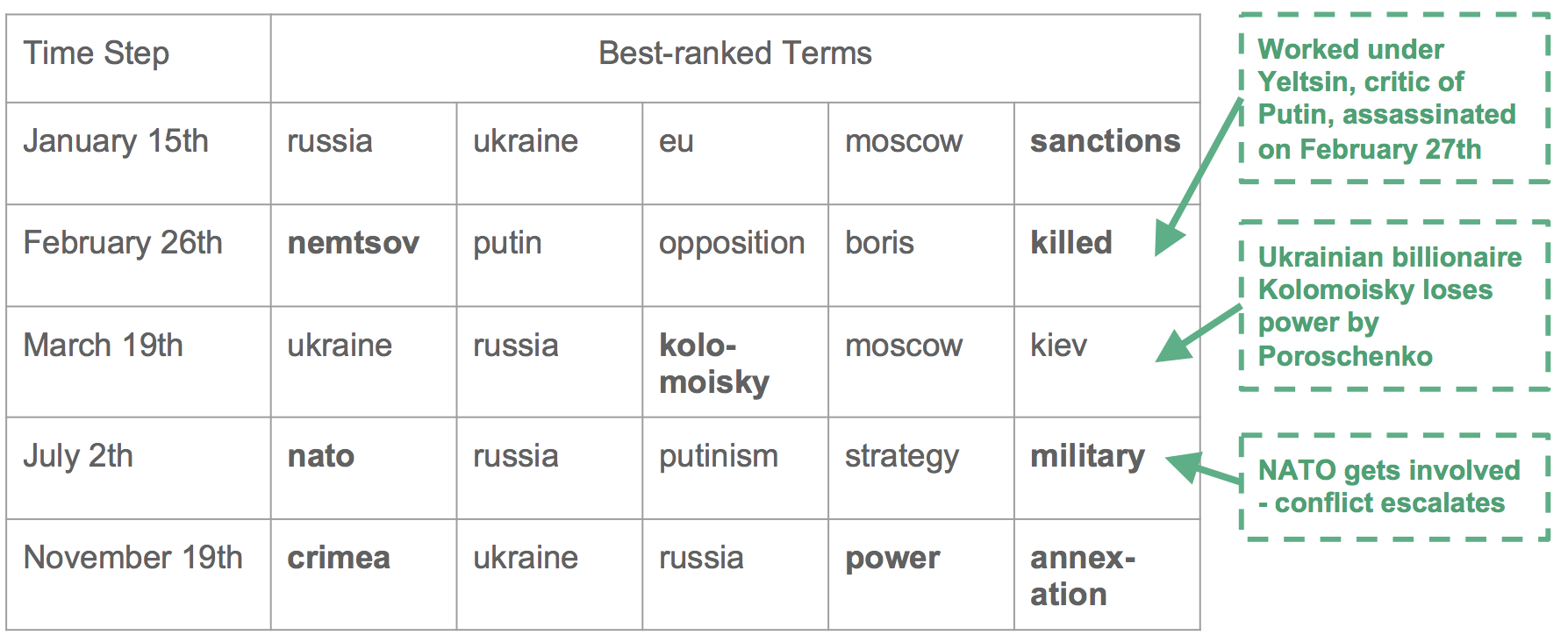
For NMF over time, the NMF algorithm was applied on separate time steps of the data and then connected using a similarity metric, thus creating a topic river with evolving and emerging topics. By using extensive cleaning of the vocabulary during pre-processing, a fast data processing algorithm was developed that is able to process a year of data with around 3000 text files per day and 50 topics generated per month in circa 15 hours. The generated topics can easily be identified by their most relevant terms and associated with events happening in the corresponding time period. Example of some main topics of 2015 are:
topic #2: games, goals, wingers, play, periods
topic #3: gmt, federal, banks, diaries, reservers
topic #15: islamic, goto, pilots, jordan, jordanians
topic #16: ukraine, russia, russians, sanctions, moscow
topic #18: euros, greece, ecb, zones, germanic -
The visualization with a stacked graph over time already works well. What can be improved is the performance for large data sets in a way, that for cases when not everything can be displayed at once, approximations to the original series are built, that are less expensive to decrease load time. Other additions can be flexible visualizations with user-defined time spans to display or statistics for single topics (even if some tend to be very short-lived). Other improvements include more colors for the graph palette if there are too many topics to display at once, and, if needed, smoothing of the graph lines.
-
In this case, the Reuters Corpus was used as test data, but the developed systems are dynamic and reusable and can take an arbitrary corpus of text data to extract a topic river. Topics so far are mainly identified by their most relevant terms, which already gives a sufficient overview on the topic’s content. However, for a more comprehensive and sophisticated description of a topic, it is possible to create story lines or summaries by applying natural language processing techniques on the most relevant documents of a topic.
References:
[Blei and Lafferty, 2006] Blei, D. M. and Lafferty, J. D. (2006). Dynamic topic models. In Proceedings of the 23rd International Conference on Machine Learning, ICML ’06, pages 113–120, New York, NY, USA. ACM.
[Blei et al., 2003] Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent dirichlet allocation. J. Mach. Learn. Res., 3:993–1022.
[Cao et al., 2007] Cao, B., Shen, D., Sun, J.-T., Wang, X., Yang, Q., and Chen, Z. (2007). Detect and track latent factors with online nonnegative matrix factorization. IJCAI, page 2689–2694.
[Lewis et al., 2004] Lewis, D. D., Yang, Y., Rose, T. G., and Li, F. (2004). RCV1: A new benchmark collection for text categorization research. J. Mach. Learn. Res., 5:361–397.
[Saha and Sindhwani, 2012] Saha, A. and Sindhwani, V. (2012). Learning evolving and emerging topics in social media: a dynamic NMF approach with temporal regularization. Proceedings of the fifth ACM international conference on Web search and data mining, page 693–702.
[Tannenbaum et al., 2015] Tannenbaum, M., Fischer, A., and Scholtes, J. C. (2015). Dynamic topic detection and tracking using non-negative matrix factorization.