Student(s): Nadine Hermans, Alexander Kroner, Wim Logister, Carsten Orth, Josephine Rutten;
Supervisor(s): Dr. Gerasimos (Jerry) Spanakis;
Semester: 2015-2016;

Problem statement and motivation:
The assignment of this project was to classify an existing data set with food images provided (available at Maastricht University in the context of a research project) into the correct food category. We compared two techniques, Convolutional Neural Networks (LeCun and Bengio, 1995) with a conventional classification setup of using hand-crafted features with a Support Vector Machine (see e.g. Joutou and Yanai, 2009) on a real data set of user-submitted food images. Different data preprocessing steps and different parameter configurations for the two approaches have been applied. Their efficacy has then been validated and compared by setting up and running experiments that use these different steps and parameters.
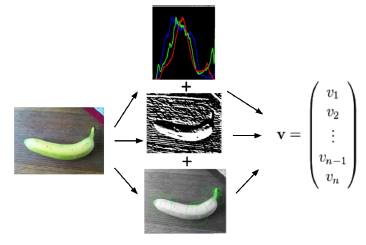
Research questions/hypotheses:
For this project, we were presented with an existing data set of food images. We then tried to answer the following question:
- What is the optimal classification approach to discriminate between the 19 different classes of food items that were defined for this data set?
More specifically:
- Which classification model (this project focussed on Support Vector Machines and Convolutional Neural Networks) performs the best on this data set?
- which methods of preprocessing and feature extraction enhance the results the most?
Main outcomes:
-
After experiments with different pre-processing methods, feature-extraction combinations and kernels and parameters, we have concluded that the Support Vector Machine with the Chi-Squared Kernel and parameters C=1 and gamma=0.1 leads to the best results using all the features (Bag of Features, Gabor filter and Histogram features) on the by GrabCut pre-processed dataset. GrabCut (Rother et al.,2004) separates background from the object by coloring the background black.
-
A final architecture has been decided on after literature research of Convolutional Neural Networks. With this architecture, results achieved by the CNN are a little bit worse than that of the Support Vector Machine, but the results do not differ much.
-
In both approaches, problems have been encountered with the dataset which is extremely unbalanced. Therefore, most instances will be classified with the most frequent label. Thus, balancing of the data is necessary. Results obtained are better with a reduced balanced dataset (using fewer than all 19 classes and making sure the number of instances per class are equal), increasing the performance while decreasing the number of labels. Moreover, the high variation of types of images within a class and the variation of quality of the pictures makes classification challenging.
-
Both approaches have their own advantages and disadvantages. While SVMs are faster to train, simple to implement and robust to over-fitting, features have to be extracted and many parameters have to be tuned. CNNs do not have as many parameters to choose and features will be extracted automatically. However, there has to be decided on an architecture and training may take a while.
References
Joutou, T. and Yanai, K. (2009). A food image recognition system with multiple kernel learning. In 2009 16th IEEE International Conference on Image Processing (ICIP), pages 285-288. IEEE.
LeCun, Y. and Bengio, Y. (1995). Convolutional networks for images, speech,and time series. The handbook of brain theory and neural networks, 3361(10).
Rother, C., Kolmogorov, V., and Blake, A. (2004). Grabcut: Interactive foreground extraction using iterated graph cuts. ACM Transactions on Graphics (TOG),23(3):309-314.